How do databases work
A database has the requirements of storing data and being able to retrieve that data when queried.
A simple database outlined in Designing Data Intensive Applications shows a simple append only file to store key-value pairs. A Set function appends a key-value pair to the end of the file which is a fast operation. However the Get function needs to scan the entire file to find the latest occurrence of the key it is looking for.
In order to efficiently find the value for a particular key in the database we need an index data structure. The index works similarly to a dictionary, if we need to find a word ‘cat’ we don’t just read the entire dictionary from front to back. We first go to the section of the book that contains words starting with ‘c’, then from that look through the words that have ‘a’ as their second letter and so on. Searching becomes much faster which means reads become faster.
The index is an additional data structure that tracks where these keys are stored in disk. Maintaining an index incurs overhead, especially on writes as we now need to update the index file as well to keep track of additions and deletion of data. Trade off to reduce write speed to increase read speeds.
B-Trees
The most common data structure used to keep track of indexes in SQL databases are B-trees.
Database rows are stored in fixed-size blocks or pages which closely resembles how disks are arranged. Each page can be identified by an address, just like a pointer in C but on the disk instead of in memory.
The index is stored on a B-Tree structure on disk. A page is designated as the root of the B-tree and contains several keys and references to children pages. Each child page is responsible for a continuous range of keys.
If we were to lookup user_id = 251, in the root table we find the reference that stores the pages containing the user_id’s from 200 to 300. Then that table contains references for the user_ids from 200 to 300 in steps of 20. We continue through the reference containing keys from 250 to 270 which brings us to the leaf page containing the reference for the page with user_id = 251
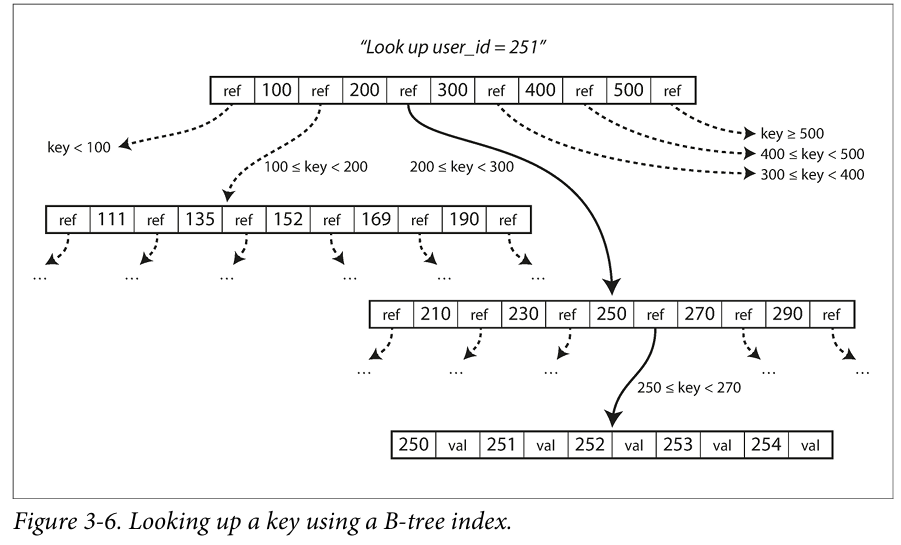
This tree always rebalanced as required when data is inserted or deleted. A B-tree with keys will always have a depth of . Most databases can fit into a B-tree that is three or four levels deep, so you don’t need to follow many page references to find the page you are looking for. (A four-level tree of 4 KB pages with a branching factor of 500 can store up to 256 TB.)
Indexing
Indexes are commonly made for primary keys. For example if we had the following example table Users.
| id (PK) | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Calvin |
| 4 | Devon |
| 5 | Edward |
| … | … |
| 1000000 | Aaron |
| For the Users table the primary key is id and we have 1,000,000 users. | |
| For the query: select * from Users where id = 5; | |
| The database would recognise that the id column has been indexed so it can scan the index data structure and find the correct id quickly in . |
Now for the query: select * from Users where name = ‘Aaron’; The name column has not been indexed, therefore the database has no idea where the table row containing a name Aaron is located. It also isn’t guaranteed for the name Aaron to occur only once so it must do a linear scan, , of the entire database in order to find all table rows containing Aaron which takes far longer than looking up an index. To solve this we can actually create an index for the name column as well if we wanted to. The database will store and manage another B-tree in order to get faster reads for any queries filtering by name.
The trade off for having another B-tree is having higher reads for the name column but will reduce overall write speeds for any data being added or deleted from the Users table as the database now needs to also update the indexing for two B-tree structures. A table can contain many columns, introducing indexes on every single column will increase read speed but will also drastically harm write speeds. Adding indexes is part of performance tuning, it should be used to speed up common query operations that are not indexed.