What is Consistent Hashing
Consistent hashing is a hashing technique such that when a Hash Table is resized, only keys need to be remapped on average where is the number of keys and is the number of slots.
It is a common technique in distributed systems where servers or databases can be added or removed/fail. How do we allocate load, how do we redistribute the load during a failure?
In traditional hash tables, changing the number of slots causes nearly all keys to be remapped as the mapping is usually defined by a modular operation.
Consistent hashing operates by assigning the data objects and nodes a position on a virtual ring structure (Hash Ring). Consistent hashing minimises the number of keys that need to remapped when the total number of nodes changes. We hash the nodes/servers and put them on the hash rings. When we are putting data objects onto the hash ring we hash the key and traverse clockwise until a node is found. Then the data is stored on that node.
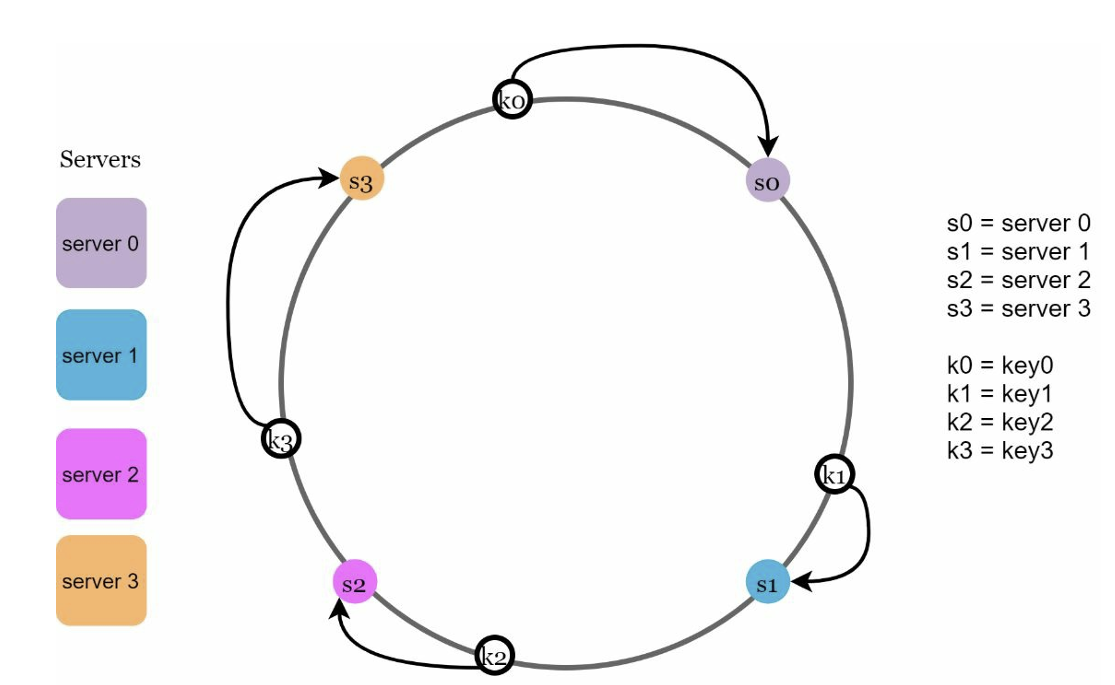
If a node goes down e.g s0 in the scenario above then k0 will map to s1 instead.
If a node is added between k0 and s0 then k0 will map to the new node.
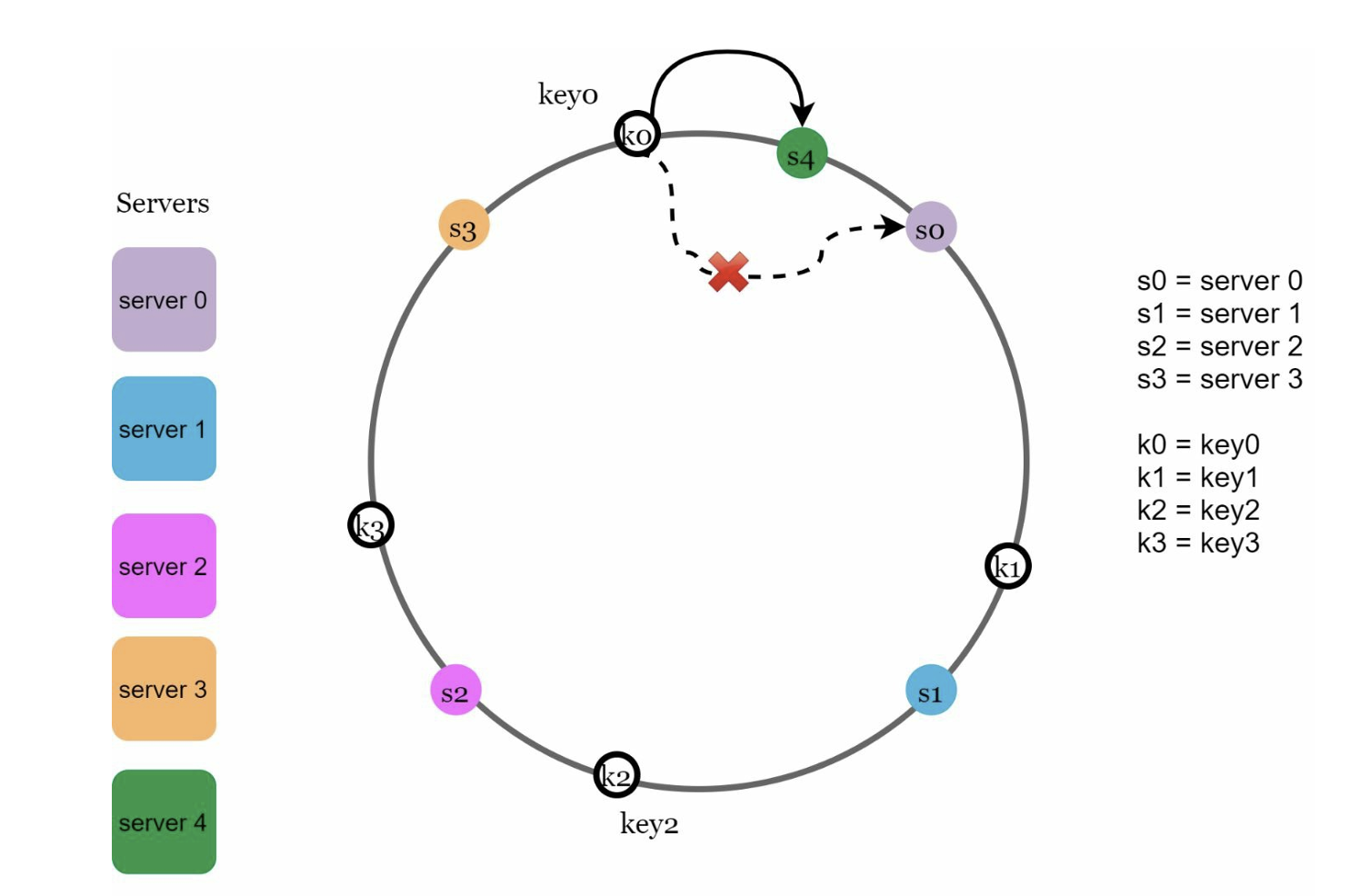
The purpose of the hash ring is to distribute load evenly across all servers such that each server has an average number of keys equal to where k is the number of keys and N is the number of nodes.
Virtual Nodes
However there is a possibility that the nodes, keys or both are not distributed uniformly.
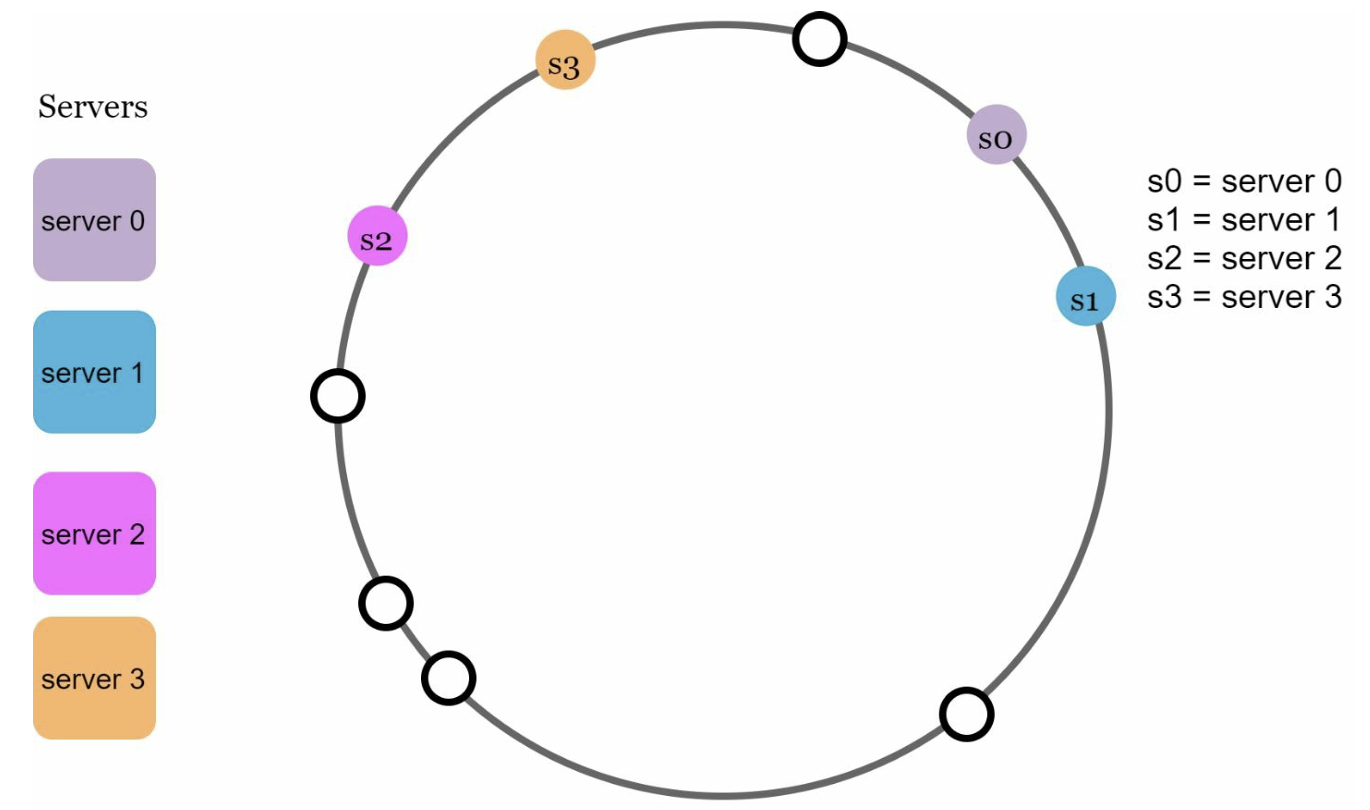 In this scenario s2 is responsible for 4 keys, s0 for 1 key and s3 and s1 responsible for 0. To prevent overloading a single server we need to uniformly distribute the servers around the ring. Adding more physical servers can be expensive. We can instead add virtual nodes. A virtual node a single server assigned to multiple different positions in the ring. Doing this can redistribute the load more uniformly without more physical servers.
In this scenario s2 is responsible for 4 keys, s0 for 1 key and s3 and s1 responsible for 0. To prevent overloading a single server we need to uniformly distribute the servers around the ring. Adding more physical servers can be expensive. We can instead add virtual nodes. A virtual node a single server assigned to multiple different positions in the ring. Doing this can redistribute the load more uniformly without more physical servers.
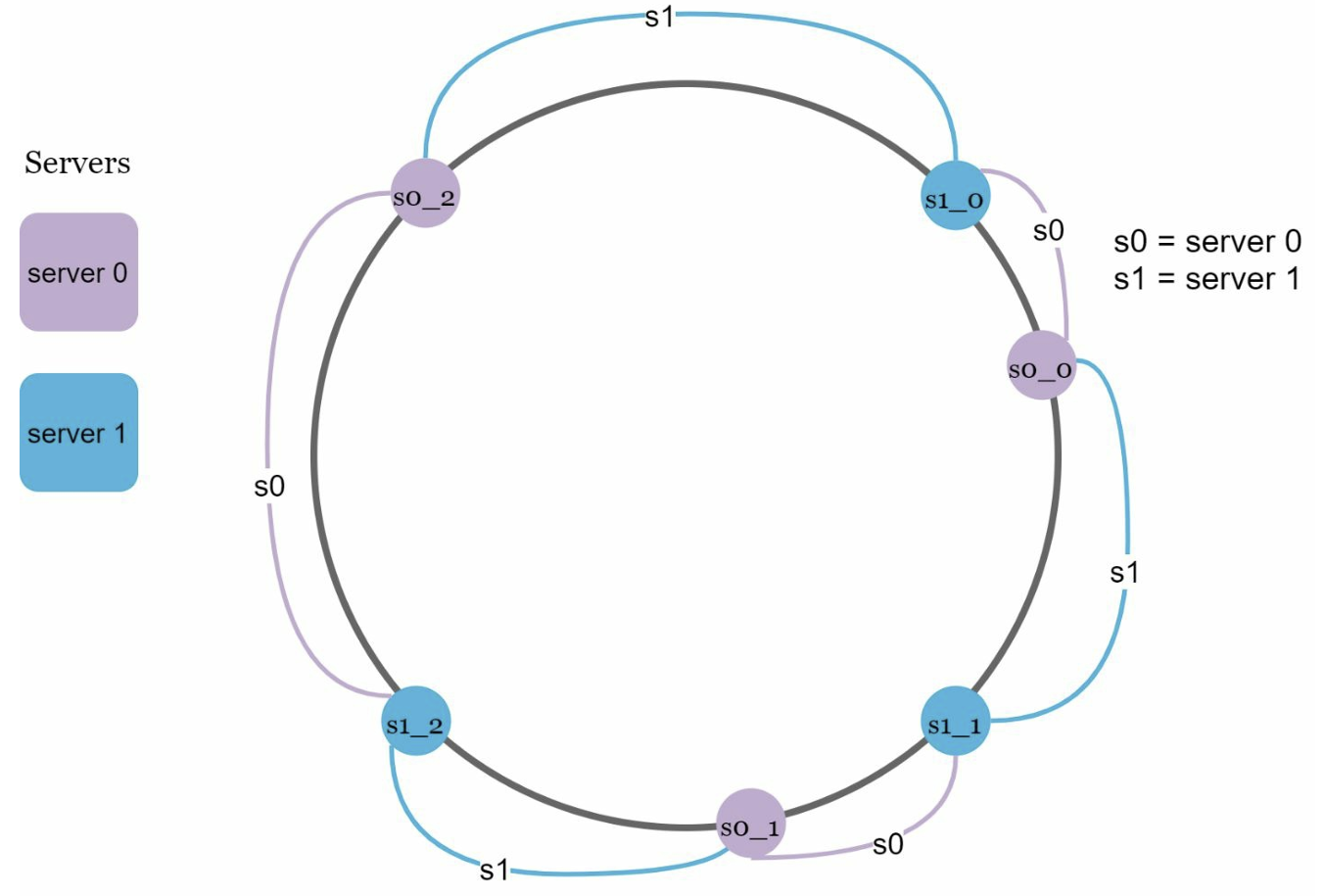
Implementation
A self balancing Binary Search Tree is used to store the positions of the nodes on the hash ring. The BST data structure is either stored on a centralised, highly available service or stored on each node.
The insertion of a new node results in the movement of data objects that fall within the range of the new node from the successor node. Each node might store an internal or an external BST to track the keys allocated in the node. The following operations are executed to insert a node on the hash ring:
- Insert the hash of the node ID in BST in logarithmic time
- Identify the keys that fall within the subrange of the new node from the successor node on BST
- Move the keys to the new node
The deletion of a node results in the movement of data objects that fall within the range of the decommissioned node to the successor node. An additional external BST can be used to track the keys allocated in the node. The following operations are executed to delete a node on the hash ring:
- Delete the hash of the decommissioned node ID in BST in logarithmic time
- Identify the keys that fall within the range of the decommissioned node
- Move the keys to the successor node